Chapter3&4 Database Storage
Record在硬盘文件中存储的方式
-
Heap file organization
Record可以放在文件里的任意地方,一旦放了就不会再动。当有
-
Sequential file organization
-
Multitable clustering file organization
-
B+tree file organization
-
Hashing file organization
Chapter.5 Buffer Pool
5.1 Buffer Pool结构
这段主要说明Page在内存中如何存储,与磁盘存储不同,内存存储涉及到了诸多读写、事务、日志操作,磁盘中存储page一般使用LSM或者B+Tree,而内存中一般直接使用HashMap。
如果单指存储的话,page在内存中则是紧凑的排在一起,可以理解为单位为4k的数组。这个数组称为Buffer Pool,里面的每个单位叫Frame,之所以不叫Page是为了做区分,计算机领域中概念模糊的词语太多。
实际上,不可能每次去内存里找个Page都要遍历Buffer Pool,这里用一个Map来做映射,Key为Page ID,Value为在Buffer Pool中的偏移。这个Map称为Page Table。
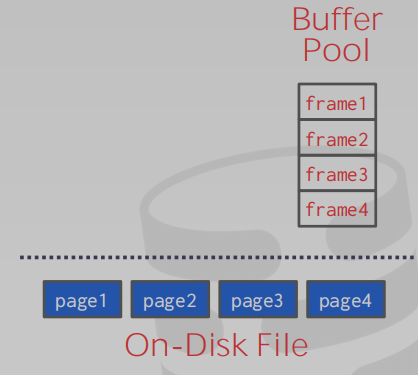
PageTable的作用除了寻找内存中缓存的Page,同样也可以存Page相关的MetaData,用于跟踪当前Pool中的Page是什么状态。MetaData主要有两种:
- Dirty Flag:记录这个page是否被修改,改了就脏了,脏了就不能用了。
- Pin Counter:记录这个page当前有几个线程在查询,该count为0才能进行写操作。
可以看出,Dirty Flag保护读操作,Pin Counter保护写操作。想要使这两个MetaData生效,那必然需要锁,数据库中锁的概念分为Latch和Lock。Lock作用于表、数据库,Latch作用于内部数据结构、内存区域等等。
- Locks
- 持续在整个事务过程中
- 保证事务隔离
- 支持事务回滚
- Latchs
- 持续在单个操作过程中
- 保护内部数据的线程安全
- 不支持事务回滚
然而到目前为止只是概念上的Buffer Pool,实际上真的在内存中分配Buffer Pool的空间时,有两种策略。
- Global Polices:所有事务共享Buffer池
- Local Polices:一个事务对应一个Buffer池,不用考虑其他事务,但是需要支持共享page。
5.2 Buffer Pool 优化策略
Buffer的基础非常简单,无非就是内存当跳板,内存有想要的page就拿,没有就去磁盘取,但实际实现并不简单,下面是四种主要的优化细节。
-
Multiple Buffer Pools
Buffer Pool的很多操作,例如fetchPage、deletePage等等都需要把整个缓冲池锁住,锁的粒度太大,没有并行性。所以需要多个缓冲池。
多个缓冲池核心设计难点在于给你一个Page ID,你要知道这个Page在哪个池子里。一般有两种做法:
- Object ID: 例如Orcal和SQL Server有额外的列(Object Number)来保存信息,而PostgreSQL只有page id 与 slot number。只需要将池子的ID存到额外列即可。
- Hashing: Mysql中就很简单的通过hash来查找page的所在池,只需要hash一下page id,结果就是所在池中的位置,对结果取模就是所在池子编号。
两种方法都不是代价很高的操作,只能说设计理念不同。
-
Pre-Fetching
预取是加速最基本的思路。以下图为例,Disk Pages存储的是一个序列化的B-Tree,Tree的节点为一个page。在磁盘上,这些数据是连续的,可以顺序IO。但实际上当我想执行
select * from t where v between 100 and 250,操作系统会在读到page0时,预读取page 0 1 2,这是合理的,然而在读到page3时,预读取page 3 4 5,因为这就很冗余,我们只需要page 3 和 5。本质上是操作系统不理解我们基于树的存储方式,而数据库系统可以做到。当然,具体怎么实现恐怕各个存储引擎都有各自的方式,这们课对此也仅仅是提了一嘴。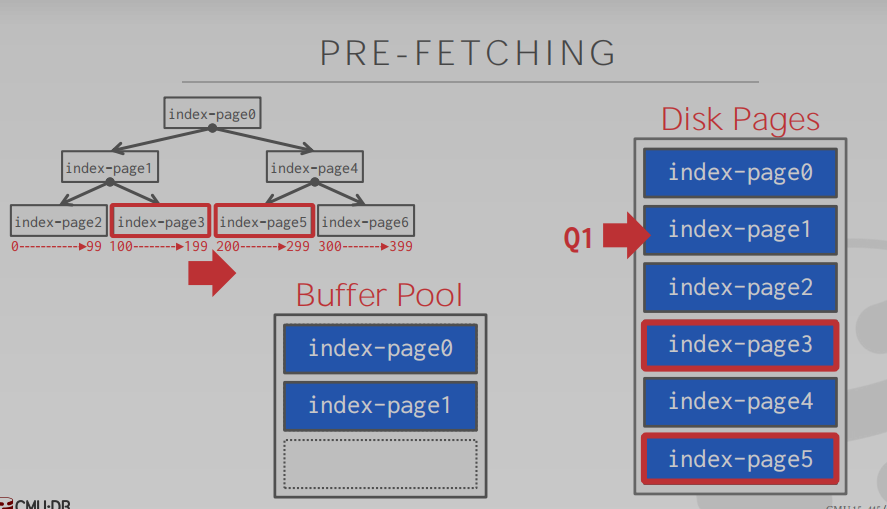
-
Scan Sharing
扫描共享四个字已经很明白的说明了这个优化方向。目前貌似只有DB2和SQL Server才完全支持。
举个例子,
select SUM(val) from A与select AVG(val) from A,都需要遍历整个表。假设表中有6行,buffer pool能存3行。Sql0执行到一半,pool里有page012了,此时012即将替换成312,假设替换完了,Sql1执行了,那么page0又要回到pool,非常蠢。而在扫描共享的情况下,Sql1会去和Sql0同步读,一起用buffer pool,例如刚才的场景中,Sql1执行了,那就和Sql0一样,从page3开始遍历,遍历完之后再自己从头遍历,共享部分缓存,减少IO次数。只是这个例子我已经头皮麻烦,难以想象更复杂的sql场景中如何实现。
-
Buffer Pool Bypass
绕过缓冲池五个字说的也很明白了,就是不用缓存池。一般操作中间结果或扫描量不大临时查询才用该策略。
举个例子,连续遍历操作,例如
select SUM(val) from A这种,可以不走缓冲池避免污染池,直接放在本地缓存,查询完成的时候,这些page全部free掉就完事了。这样做,单纯是因为走缓冲池开销更大,而不是否认缓冲池的作用。在Informix中,这个操作叫light scan,基本主流数据库都支持这个操作。
5.3 OS Cache 相关
先说一下Direct IO。标准IO是用户程序把数据从page cache里copy到用户控件,MMAP是用户程序直接操作page cache,Direct IO是用户程序绕过page cache。Direct IO一般使用较少,而MMAP虽然少了一次copy,但是容易触发page fault,page fault的开销比mencpy大太多了,这里以后有机会详细深入了解。
数据库系统底层依然是系统调用,read和write都是走的OS的内存管理和磁盘管理。也就说,在正常IO的情况下,数据库依然会走page cache,和上面的优化4同理,OS层面的page cache不一定要走,可以用Direct Io绕过。
Direct IO和Buffer Pool Bypass本质作用相同。
- 缓存命中率的数据没必要走缓存。
- 避免污染缓存池,削弱其他进程或线程的缓存有效性
主流数据库中唯一依赖OS Cache的PostgreSQL,他们通过牺牲一些性能来减少一些系统的维护量。
Chapter.7 B-Tree
B-Tree和HashMap一样,都是为了索引,但是Map不适合范围索引,所以只能用B-Tree,B-Tree中B+Tree最屌。
//todo hash
Leaf Node
答案不唯一,可以存指针也可以存数据,PostgreSQL存指针,Mysql存数据。

B+Tree VS B-Tree
简单说,B的Key不可以重复且可以保存在任何节点,而B+的Key可以重复且只能保存在叶子节点。
这意味着如果要对一个节点做变动,B-Tree需要上下同时递归遍历改动,需要两个latch,而B+Tree只需要向上改动。多线程情况下B+Tree优于B-Tree。
另外,所有数据在最后一层,方便范围索引。
Clustered Index
但聚簇索引的意思是: 对于面向Page的存储引擎,所有的Page是按主键的顺序排序的,同时Page内的Tuple顺序和主键顺序也是一致的。
B+Tree Design Choices
-
Node size
Node大小主要看存储介质,存储在磁盘的话一般以M为单位,这样可以减少IO次数分担读的压力,存储在内存大小一般适合512bytes,一般cacheline大小为64b、32b不等,如果page越大,越容易碎片化。
Node大小同样取决于WorkLoad类型,一些点查询喜欢page小,一些顺序扫描就喜欢page大,看情况。
针对该点:在mongodb做了大量实验,叶子节点设为4KB与128KB,存储了100w个512B的数据,可以发现单点查询小叶子更有优势,范围查询大叶子更有优势。
-
Merge Threshold
这里对我而言唯一有用的可能就是,不断的Insert和Delete会导致Page合并和拆分,这两者代价都很大,树也会逐渐不平衡,所以需要偶尔重建索引。(45讲理有说过,记得回去看看)
-
Variable Length Keys
有几种方法可以解决:
- Pointers:如其名,key只存指针,IO++。
- Padding:如其名,补0直至tuple适合page大小,常见的varchar(xxx)就是典型的例子。
- Key Map / Indirection:和Slotted Page一个套路,Page前面
-
Non-Unique Indexes
-
Intra-Node Search