部分数据实例
Accounts
0 73cc29d320aabdad
1 b56a14dac2a53487
2 dd0d4423b3a76ddc
3 dd4558dd9a60aa30
4 b4a1ad3adbbbaa23
5 ba73abca485d44ad
6 cbb055c1d2d6146c
7 bccd087b572aba40
8 9ba12dc7c9c2cd2d
9 b457d5dad2ba0b41
10 6c31b59aaa0aad4d
Relations
4831342 134d0902bdd0641b 2618346 ad99ac3738bca8ca
4344645 da57218c467d4695 3429183 654b5dd92dda2d2b
2572891 c93d9195c2a15a62 2248096 a6243abb3a3bcbbc
1912430 adcbc16d41492a0d 794101 a3ddb7504963571a
4262423 5a5d1bb29ba65c8b 3767429 86c9b0acba8a7a0b
3605550 b0dddddaa0b76687 1728813 33b4658d9c0bc902
2633634 dcabda0300db8b06 251138 b7cacc687adb9008
1022533 1ca9b4bbcabab9ba 496889 cb05dac9bdcd1987
3922970 a6cbb04c1ab9b9aa 1929729 6d9bb6a653baa0c5
2677481 1bd497acdd9dba7c 1275724 141d20da73a196aa
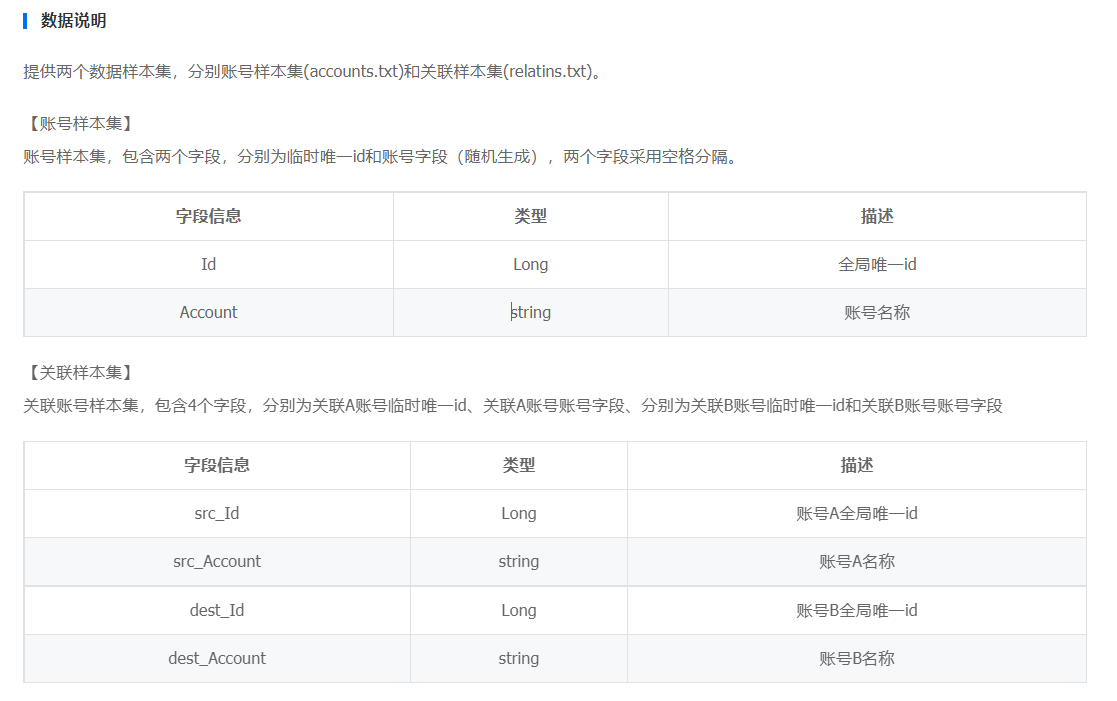
注意,账号长度为固定的16位
输出格式:比如 4 5 6成簇,那么输出最小的id 4,同时按序输出整个簇里所有账号id对应的账号
读Accounts
老生常谈多线程IO,首先对文件进行逻辑分割成线程数。MMAP读,同时进行解析。
很明显,Relation文件里的账号字符串是不需要的,只要在Account里读即可。
这里有一个最最最核心的优化点,也是我不能进1s的最大原因。
读account的时候,不需要把16位的账号也读出来,因为从头到尾account根本不需要我们处理,同时整个过程也没有断电操作,只要在数组中记录它在buffer中的位置即可,到时候写的时候直接0拷贝。
读Relations
同样多线程读,分块无锁化操作。遇见空格直接跳16位。这时候可以获得并查集需要的两对数据,src和des。
这里的关键点在于:
一开始的直接思路是创建一个二维数组edges,第一维度是src或者des,第二维是关系对的总个数。
但这种做法肯定是很蠢的,多线程读文件然后写到数组中,需要用CAS或者写锁保证一个个写进来,那多线程读就根本没有了意义。
所以首先的改进就是多空间换低并发,和多段锁的策略是类似的。把二维数组升成三维数组,一维是src和des,二维是线程个数,三维是总对数除以线程个数。
但这样做涉及到一个老生常谈的问题:虽然多维数组在内存中是顺序排放的,但多维数组顺序读写是必然比一维数组慢的。
由于两者都是顺序排放,所以顺序读写的话,CPU缓存是不受影响的。关键在于多次寻址的计算。
如果是一维数组,那么寻址只需要address+offset。
如果是多维数组,那么寻址需要address + (一行元素个数)*(当前行) + offset 这样更复杂的计算。
同时java还会对数组有边界检查,也就是本来只要做一次边界检查,现在需要做两次!
所以在考虑性能优化的时候,能不用多维尽量不要用多维,最好压缩成一维数组使用。
所以读关系文件最大的两个优化点在于,多段锁机制 + 数组降维。
线程遮盖
没有必要先读account,再读relation。可以直接先开启读account线程组,然后开启读relation线程组。如果读relation和计算并查集太快,那么写之前就等待account读取完毕。
并查集优化
传统的并查集写法:路径压缩+按秩合并。但是这种做法不能满足每个簇里的father都是最小账号。
所以在初始化relation数组的时候,直接把较小的作为父亲。
for (int i = 0; i < NUM_ACCOUNTS; i++) {
relationArray[i] = -1;
}
for (int i = 0; i < numThreads; i++) {
for (int j = 0; j < edgesNum[i]; j++) {
int srcId = edges[0][i][j];
int dstId = edges[1][i][j];
if (relationArray[srcId] == -1 && relationArray[dstId] == -1) {
int min = Math.min(srcId, dstId);
relationArray[srcId] = min;
relationArray[dstId] = min;
} else if (relationArray[srcId] == -1 && relationArray[dstId] != -1) {
relationArray[srcId] = relationArray[dstId];
} else if (relationArray[srcId] != -1 && relationArray[dstId] == -1) {
relationArray[dstId] = relationArray[srcId];
} else {
if (relationArray[dstId] < relationArray[srcId]) {
relationArray[srcId] = relationArray[dstId];
} else {
relationArray[dstId] = relationArray[srcId];
}
}
}
}
然后在对relation关系对进行遍历的时候,对数组再进行一轮扁平化计算,也就是把整个并查集变成只有两层。
boolean flag = true;
//保证整个并查集只有两层
while (flag) {
flag = false;
for (int i = 0; i < NUM_ACCOUNTS; i++) {
if (relationArray[i] != -1) {
if (relationArray[relationArray[i]] != relationArray[i]) {
relationArray[i] = relationArray[relationArray[i]];
flag = true;
}
}
}
}
然后保证这两层里面每一个节点的父亲都是当前簇里的最小值
//保证并查集里所有节点的fa都是最小账号
for (int i = 0; i < NUM_ACCOUNTS; i++) {
if (relationArray[i] != -1) {
if (relationArray[i] > i && relationArray[relationArray[i]] > i) {
relationArray[relationArray[i]] = i;
relationArray[i] = i;
} else if (relationArray[i] > i) {
relationArray[i] = relationArray[relationArray[i]];
} else {
relationArray[i] = relationArray[relationArray[i]];
}
}
}
写优化
由于结果要求输出每个簇的最小id,以及按序输出这个簇里所有账号。
这里由于输出文件大小是确定的,直接mmap一块100m左右的内存,进行随机写。
写的时候本质就是多线程遍历account,但同时要进行一些提前预处理。
对每个节点对应簇的具体个数要提前存储好。
对每个节点应该写在那个位置。
大块的mmap写完之后,多线程写入即可。