[TOC]
AtomicLong
考虑一个最基本的情况,统计接口调用次数,一般用AtomicLong的incrementAndGet(),想查看就用Get()。
低并发用无锁比较合适,但是高并发用无锁,会让大量CPU处于空转,性能不高。
再由于使用Atomic系列变量经常用来统计个数,写操作是远大于读操作的,分布式思想应运而生。
与其让N个线程去写一个Atomic,不如让N个线程去写X个Atomic,最后需要get的时候汇总结果即可。AtomicLong就是基于这种思想。
LongAdder
Doug lea本人说过LongAdder是比AtomicLong高效的。
Cell解析
LongAdder最重要的成员变量就是Cell数组,Cell就是被改写的AtomicLong类。Cell源码如下。
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
可以看到Cell基本实现和AtomicLong区别不大,除了unsafe优化以外,最大的区别在于加入了Contended注解。
@Contended,一言以蔽之就是去解决缓存行伪共享问题。
CacheLine是什么?
CPU三级缓存架构中,获取缓存的最小单位是CacheLine,概念和磁盘的最小获取单位以及内存的最小获取单位都为4K类似,CacheLine一般为64字节,具体多少可以通过相关命令去查看。
缓存一致协议(MESI)
当多个处理器都涉及L3共享缓存的更改时,各自的缓存中对应的区域会各不相同。为了解决缓存一致性问题,读写时需要根据一些协议来进,最常用的是MESI协议。
-
Modified(修改):该缓存行仅出现在此cpu缓存中,缓存已被修改,和内存中不一致,等待同步至内存。
-
Exclusive(独占):该缓存行仅出现在此cpu缓存中,缓存和内存中保持一致。
-
Shared(共享):该缓存行可能出现在多个cpu缓存中,且多个cpu缓存的缓存行和内存中的数据一致。
-
Invalid(失效):由于其他cpu修改了缓存行,导致本cpu中的缓存行失效。
当缓存行处于Shared状态时,会时刻监听其他cpu对使缓存行失效的指令(即其他cpu的写入操作),一旦监听到,将本cpu的缓存行标记为Invalid状态。
说白了,让缓存行失效是一种保证缓存一致的重要手段,但是这种手段会在某些情况下成为拖累效率的罪魁祸首。
伪共享(false sharing)问题
缓存一致性协议针对的是缓存行,如果某个cpu0和cpu1一起share了缓存行l1,这个缓冲行中有a和b两个连续数据。
当cpu0修改了a,根据MESI,cpu0要把l1设为invalid,然后写入内存。
当cpu1需要读l1,根据MESI,cpu1要从内存中重新加载l1。如果cpu1再需要修改b的话,那么就往复循环,所谓的sharing甚至不如没有缓存速度快!
伪共享解决方案
解决方案其实很简单粗暴,既然针对的是一个缓存行出现多个连续变量,那么就填充这些变量,让它们别挤在一行,典型的空间换时间。虽然让寸土寸金的缓存可用空间少了很多,但是优化了效率。
@Contended本质也就是在这个类中加入一些无用的long变量。
回到LongAdder,Cell数组为24字节(16字节的缓存头加上8字节的value),一个CacheLine能存下不止一个Cell,所以会面临伪共享问题,所以要用@Contended。
Add方法解析
// x:累加值
public void add(long x) {
// as:累加单元数组 b:未竞争时基础值
Cell[] as; long b, v; int m; Cell a;
// 进入if语句需要处于竞争状态
// 1.cells不为空,说明发生了竞争
// 2.对b进行CAS累加,如果成功则直接返回,如果不成功说明发生了竞争
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
// 以下为4个可以调用longAccumulate的条件
if (as == null || // as为空,需要创建as
(m = as.length - 1) < 0 || // as创建了但是长度为0
(a = as[getProbe() & m]) == null || // 当前线程的cell为空
!(uncontended = a.cas(v = a.value, v + x))) // 当前线程cell CAS失败
longAccumulate(x, null, uncontended); // 进入cell数组创建的流程
}
}
longAccumulate方法解析
有点复杂,留个坑,未来有空慢慢理顺。
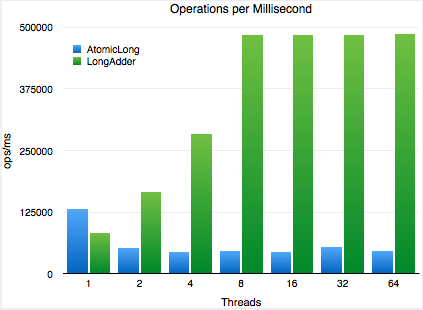
两者性能测试
个人测试
对LongAdder、AtomicLong、同步变量同时使用进行测试。
4线程
Benchmark Mode Cnt Score Error Units
LongAdderTest.testAtomic thrpt 2 84567975.912 ops/s
LongAdderTest.testLockAdder thrpt 2 45816804.223 ops/s
LongAdderTest.testLongAdder thrpt 2 1409567837.928 ops/s
16线程
Benchmark Mode Cnt Score Error Units
LongAdderTest.testAtomic thrpt 2 0.083 ops/ns
LongAdderTest.testLockAdder thrpt 2 0.046 ops/ns
LongAdderTest.testLongAdder thrpt 2 1.410 ops/ns
可以发现在并发的情况下,testLongAdder > testAtomic > testLockAdder。
官方测试