虚拟内存
OS里非常重要的一个技术,它让程序认为自己拥有连续可用的内存,而实际上,它在物理内存中可能是零散、不规则的,甚至部分暂存在磁盘,在需要的时候进行交换。每个进程,访问的其实都是虚拟内存,虚拟内存再映射成物理内存。
说大白话,我们写程序的时候只需要考虑逻辑地址(虚拟地址),初始地址为0。但是实际在物理内存的地址需要MMU(Memory Management Unit)去映射。
内存分配
一个直接的朴素想法是,将虚拟内存和物理内存地址一一对应映射。
实际的考虑一下,内存的访问单位是Byte,假设有一个32位的CPU,内存寻址的最大地址是2^32,需要四个字节来表示。一个Byte的映射包含了物理地址和虚拟地址,至少需要8个字节。那4G的内存条有1024 * 1024 * 1024 * 4 个Byte,光映射就得至少32G,那么直接映射必然不合理。
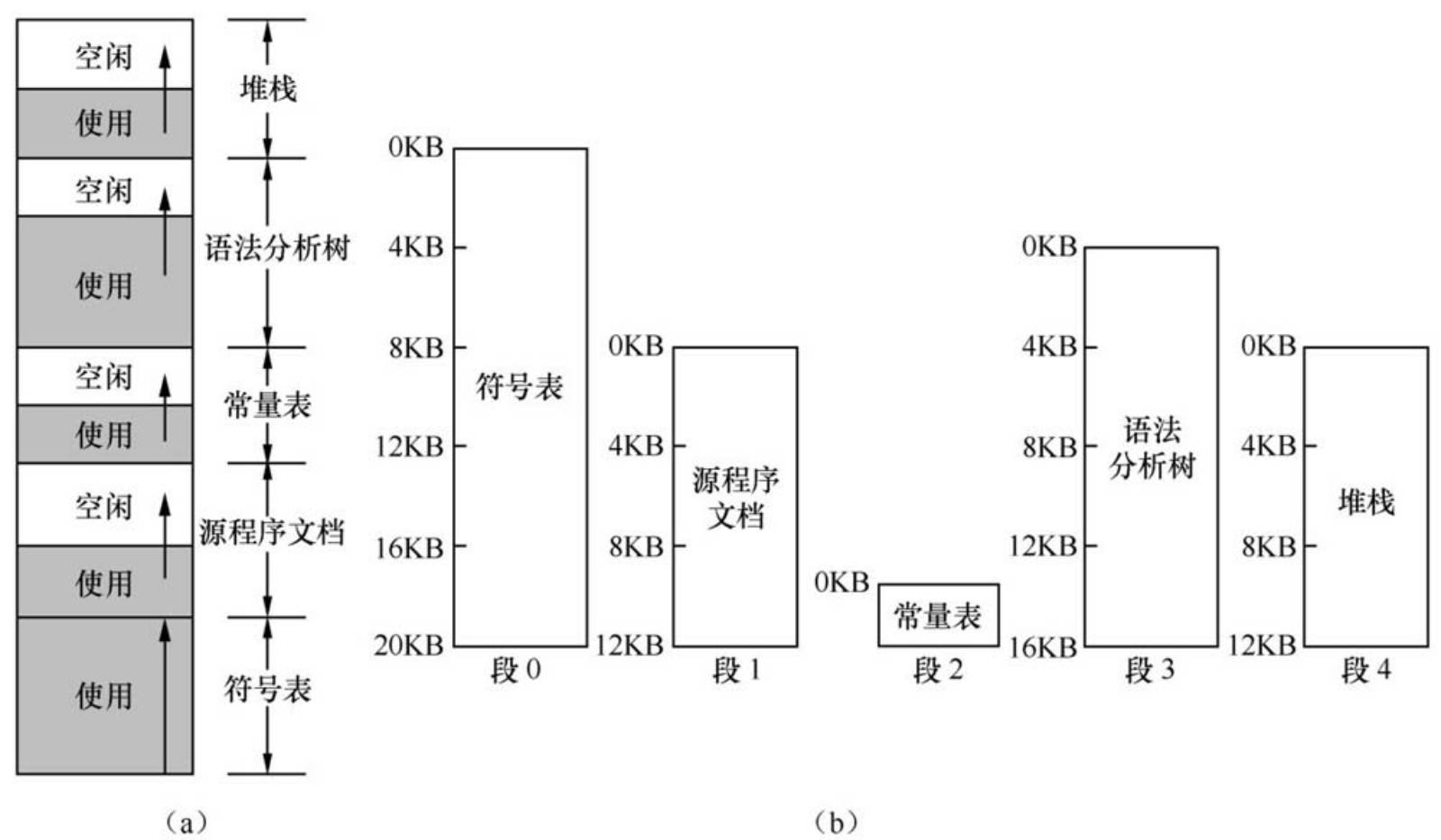
段表
段表是一个历史包袱。
它的设计理念是:程序是由若干个逻辑分段组成的,代码、堆、栈、数据等等,CPU只需要关心现在要存的数据放在哪个段的哪个部分即可。
分段机制下的虚拟地址由两部分组成:段选择子和段内偏移量。说大白话就是段的地址和段内的地址。
如图:
在Intel初代的8086CPU上,所有的内部寄存器只有16位、外部数据总线都是16位宽,是完全的16位微处理器。但是地址总线是20位,也就是物理寻址空间是1M,为了配合地址总线的设计,内存分配采用了段寻址方式。另外还有一个原因就是方便重定位。
重定位指的是程序中调用其他指令,需要根据程序的基质重新定位这条指令的地址。比如当前程序在内存的地址属于10000~11000,在10800处有个指令调用了200地址的指令,那么这个200不能直接去物理地址找,要重定位成10200。
The Linux Programming Interface这本书里说到:
Linux uses segmentation in a very limited way. In fact, segmentation and paging are somewhat redundant, because both can be used to separate the physical address spaces of processes: segmentation can assign a different linear address space to each process, while paging can map the same linear address space into different physical address spaces.
Linux用分段是一种效果非常有限的划分方式。事实上,分段和分页都一定程度上重复了,因为两者都是为进程划分物理空间地址的方法。分段可以给每个进程分配不同的线性空间,但是分页可以把相同的线性地址空间映射到不同的物理地址空间。
事实上,现在Linux已经抛弃了分段,只有分页。
个人认为原因如下:
-
复杂的内存管理。分段没有统一的方案,比如有些情况程序占用大量符号表,其他段使用较少,那么则需要整体迁移。
-
容易产生内存碎片。一旦产生内存碎片,则需要使用交换机制(把不用的进程暂时放到硬盘,需要的时候再拿回)进行处理,效率很低。
页表
分段最大的问题在于内存碎片和内存交换的空间太大。
所以分页的概念随之而来。
分段是直接把整个内存划分成了N个大区域,好处是地址连续,坏处区域过大导致处理问题时很臃肿。
分页是直接把整个内存划分成了N个小区域,这个小区域Linux设定为4K,也就是页(Page)。
假设内存为4G,则一共有 4 * 1024 * 1024 * 1024 / 4 * 1024 = 1M对映射,页表仅仅需要8M内存。
但是,每个进程都需要自己的页表,如果有100个进程,那么就需要800M的内存放页表。
所以引入了“多级页表”的解决方案。
在说多级页表之前,先想想为什么分页有用。
假如一个酒店1000个房间,如果房间全在一层楼,那么登记表的长度为1000,工作人员登记一个房间都得找半天,还浪费纸张。
如果一共10层楼,那么每层楼100个房间,那么记录只需要用楼层-房间号去记录就好了。
现实生活中,XX小区XX栋XX层XX号这样的做法就是一种很好的索引方式。
不管是内存管理,还是设计缓存,还是优化数据,不管用的是所谓的分页、分桶、分段,本质上都是利用乘法的性质建立索引,增加效率。
所以当分页只简单的分了一次,效果还是不够的情况下,则需要多级分页。
对于64的操作系统,一般是四级分页:
-
全局⻚⽬录项 PGD(Page Global Directory)
-
上层⻚⽬录项 PUD(Page Upper Directory)
-
中间⻚⽬录项 PMD(Page Middle Directory)
-
⻚表项 PTE(Page Table Entry)
TLB
多级页表虽然解决了空间上的问题,但是MMU一次地址转换就需要四次寻址,效率变低了。
解决的方法依然千篇一律,加缓存。
CPU不止有L123 Cache,对于页表,也有专门的缓存,也就是TLB(Translation Lookaside Buffer)。那么CPU在寻址的时候,就会先去TLB找,再去查页表。