前提: HashMap在JDK中的结构层次
先来一张Java.Util包的类结构(可打开大图)
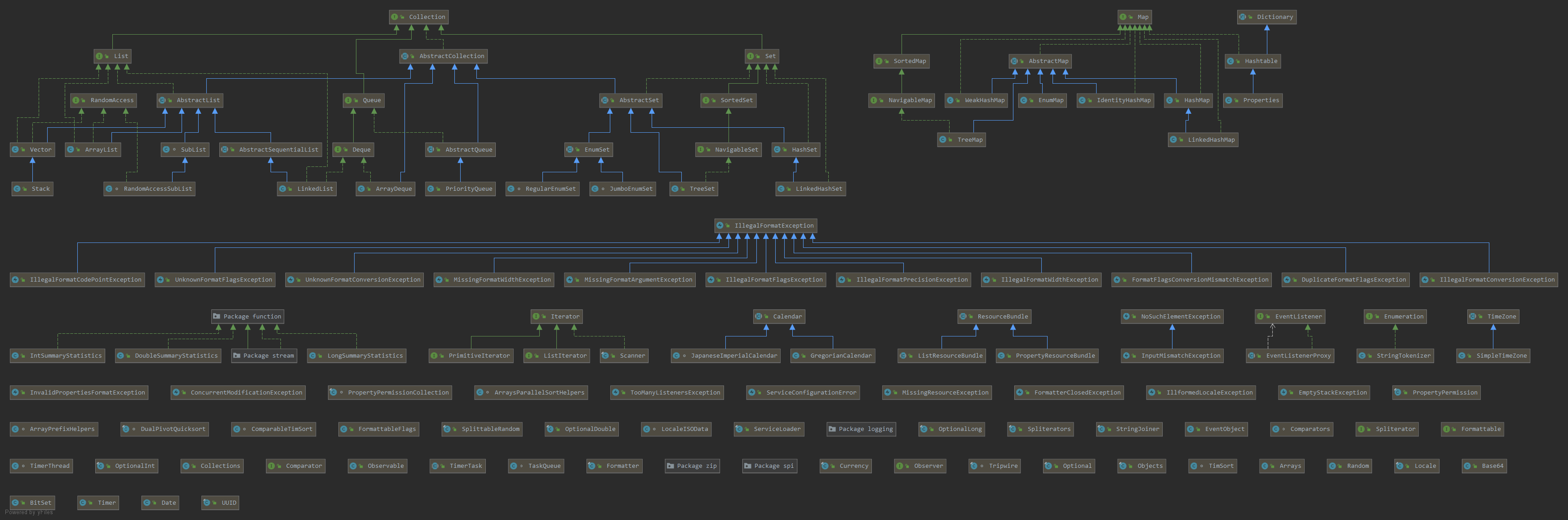
Util里主要容器类就是Collection和Map,先研究Map这一块,Map容器系列设计结构如下。
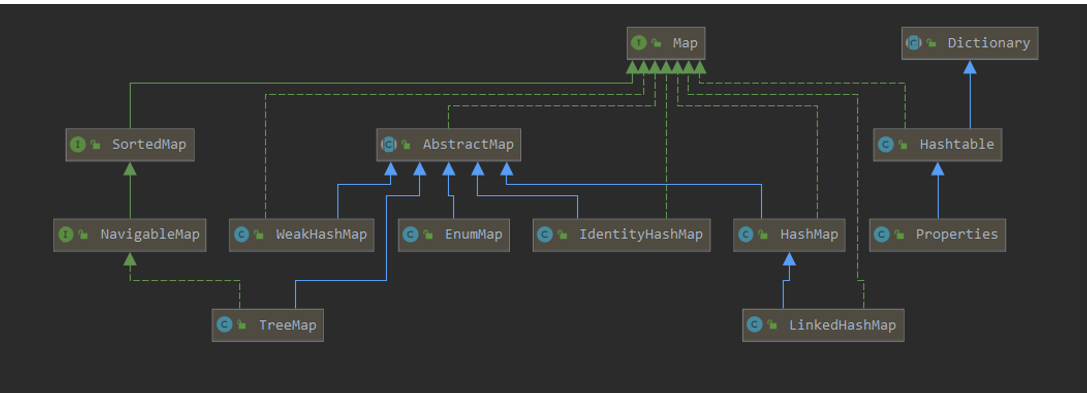
Map:Map接口设计好了所有Map基础操作的方法。
AbstractMap:
关键注释:This class provides a skeletal implementation of the Map interface, to minimize the effort required to implement this interface.To implement an unmodifiable map, the programmer needs only to extend this class and provide an implementation for the entrySet method, which returns a set-view of the map’s mappings. To implement a modifiable map, the programmer must additionally override this class’s put method (which otherwise throws an UnsupportedOperationException)。
简要概括:这个类提供了Map接口的简单实现,目的是让后续实现这个类的时候少费点功夫。如果要去实现一个unmodifiable map,只要继承这个类去实现一些方法就好。
AbstractMap仅有一个抽象方法:

要想实现一个不可修改的Map(视图Map),只需要继承这个类,实现这个方法,这样就可以返回这个map的视图了。
要想实现一个可修改的Map(正常使用的Map),就必须要实现这个类的put方法。因为AbstractMap默认自己是个视图Map。
看源码看到这里,想吐槽一点,JDK里的不可变Map,也就是Collections.UnmodifiableMap。只实现了Map接口,并没有继承这个类,两个类的作者是一个人,自己都不用自己写的类,离谱。
private static class UnmodifiableMap<K,V> implements Map<K,V>, Serializable {
//实现
}
所以到头来,Abstract的作用就只在于:实现了很多Map的基础方法,子类的其他Map,比如Hashmap、TreeMap等,可以选择性的覆盖。
但是实际上呢?HashMap、TreeMap,真的用到了AbstractMap里写的方法了吗?
Map里最关键的get()和put()方法,put()没写,get()也仅仅是循环Entry找到目标Key,和没写一样。
去StackOverFlow翻了一圈,有个类似的问题:
**Why does LinkedHashSet
下面有个JDK作者的朋友回复了:
I’ve asked Josh Bloch, and he informs me that it was a mistake. He used to think, long ago, that there was some value in it, but he since “saw the light”. Clearly JDK maintainers haven’t considered this to be worth backing out later.
Mistake解决了所有疑问。所以,HashMap其实只实现Map接口就行了,不用考虑AbstractMap。
正篇:
1.HashMap总体结构
从结构实现来讲,HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。
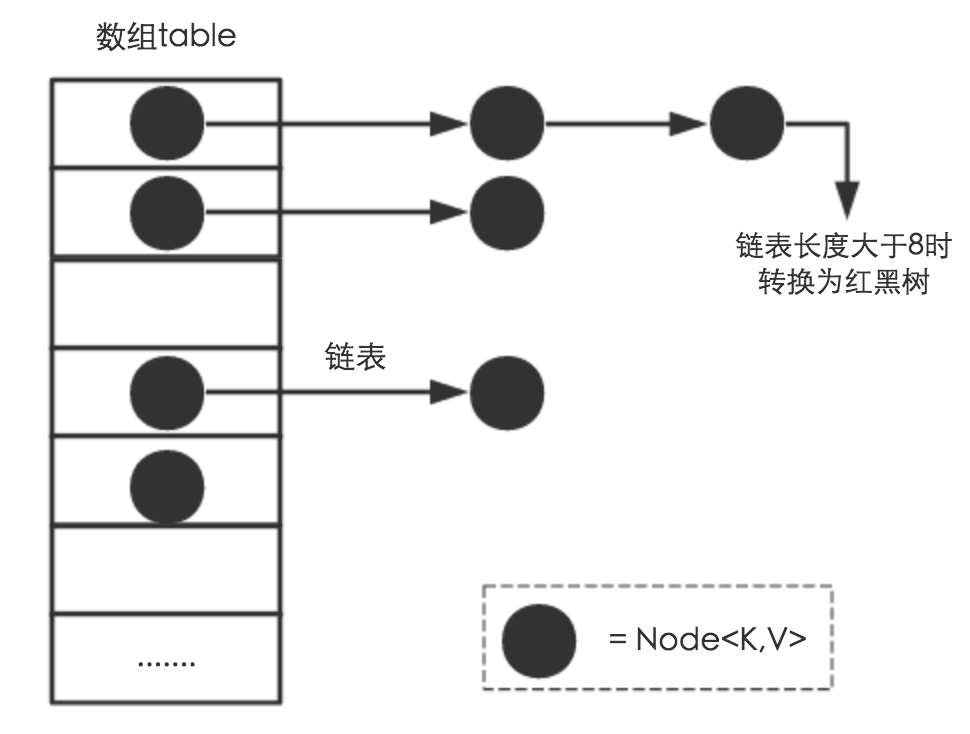
-
其中黑色的节点就是源码中的Node,整个数组就是Node[] table。
static class Node<K,V> implements Map.Entry<K,V> { final int hash; //用来确定其在table中的索引 final K key; V value; Node<K,V> next; //链表的下一个node } -
对于整体table,有几个关键的变量需要知道。
int length; // table总长度 int threshold; // 所能容纳的key-value对极限 == length * loadFactor final float loadFactor; // 负载因子 int size; // 实际node数量这里的length是2^n,而常规来说桶的大小应该是素数,相对来说素数冲突的概率要小于合数(流传结论,有待研究)。HashMap这样做的理由是方便扩容和取模,为了减少冲突,hash算法也加入了高位参与运算。具体见下文。
这里还涉及到两个细节,为什么负载因子默认是0.75,为什么链表超过8才会升级成红黑树。
-
负载因子
搜遍StackOverFlow、Quora、Google各大能搜索的地方,看了无数争论和乱科普的帖子。
我的结论是,没有任何特殊意义,纯属是一种简单的折中方案,0.5的话就要浪费一半空间,1的话不可行,所以取折中。
贴一下维基百科HashMap词条的负载因子内容作为实锤:
The performance of the hash table worsens in relation to the load factor as α approaches 1. Hence, it’s essential to resize—or “rehash”—the hash table when the load factor exceeds an ideal value. It’s also efficient to resize the hash table if the size is smaller—which is usually done when load factor drops below αmax / 4 .
Generally, a load factor of 0.6 and 0.75 is an acceptable figure.
总的来说,要是负载因子够小,内存足够,那么哈希算法哪怕很垃圾,也能减少冲突。要是负载因子太大,那么就必须要求哈希算法足够完美和均匀,否则容易冲突。0.75是一种妥协。
-
升级红黑树
首先说一下泊松分布的定义:泊松分布是单位时间内独立事件发生次数的概率分布。公式这里不贴了,泊松分布一共两个重要的变量:λ和k。λ是单位时间(单位面积)内,随机事件的平均发生率。k是发生的次数。
这里带入table,λ的定义是,用户put进某个bin的概率,k是用户put进同个桶k次的概率。
这里其实不管λ是多少,比如0.6、0.7,泊松分布所计算得进入同个桶8次的概率都低的离谱,为千万分之一。这里贴一下λ取几个常用值的表。源码注释中默认λ是0.5。
λ k = 0 k = 1 k = 2 k = 3 k = 4 k = 5 k = 6 k = 7 k = 8 0.5 0.60653066 0.30326533 0.07581633 0.01263606 0.00157951 0.00015795 0.00001316 0.00000094 0.00000006 0.56 0.57120906 0.31987708 0.08956558 0.01671891 0.00234065 0.00026215 0.00002447 0.00000196 0.00000014 0.375 0.68728928 0.25773348 0.04832503 0.00604063 0.00056631 0.00004247 0.00000266 0.00000014 0.00000001 0.6 0.54881164 0.32928698 0.09878609 0.01975722 0.00296358 0.00035563 0.00003556 0.00000305 0.00000023 0.7 0.49658530 0.34760971 0.12166340 0.02838813 0.00496792 0.00069551 0.00008114 0.00000811 0.00000071 但是源码中的解释很值得玩味:
Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity.
他说λ为0.5是因为threashold是0.75,取一个大概的值,具体0.5怎么来的没说明白,网上众说纷纭,说一下我的理解和证明。

作者只带入了扩容一次的λ,也就是0.5,实际项目中,基本都是预估好map的capacity,不会扩容太多次,毕竟创建大数组消耗的时间是相当庞大的。
事实上,以f为0.75举例,当λ接近0.375,也就是table扩容无限次的时候,bin里链表的长度为8的概率比0.5还要小六倍,数据可见上表格。这也解释了f为什么越小,越不容易冲突。
最后,由分析可得,链表为8的概率仅仅为千万分之一,红黑树并不是一种性能优化,而是一种保底手段。
-
2.HashMap功能实现
-
哈希算法
//哈希算法 static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } //哈希算法 -> table索引 if ((p = tab[i = (n - 1) & hash]) == null){ tab[i] = newNode(hash, key, value, null); }之前说了为什么table选取2的n次方,原因之一就是这里优化的table的索引计算。一般来说,当算出key的hash值后,会对数组长度 进行mod操作,而mod底层又是无限除法,性能较差。这里是对hash值和(table.length - 1) 进行 & 操作。
比如一个长度为4的table,此时table.length - 1为
0 0 0 0 1 1 1 1
比如此时hash值为
1 1 0 1 0 1 0 1
那么table的索引为
0 0 0 0 0 1 0 1
这意味着,table长度外的值统统不会考虑,变相的实现了mod运算。
另外哈希算法的话,hashmap的做法是 h & (h »> 16),这样保证了高低位的bit都能够参与hash的计算,尤其是在table长度较小的时候。
-
扩容机制
先说结论:
-
hashmap并不是在链表长度大于8就一定升级红黑树,而是先resize,resize超过64才会升级。
-
hashmap也不是链表长度小于6就会拆红黑树,而是在resize的时候对红黑树进行split操作,如果长度小于6,才会退化。
这里关于扩容有很精妙的地方。首先,扩容的第一步是申请一个长度两倍的table,其次就是要oldTab里的元素移到newTab。遍历每个bin,如果这个bin只有一个元素,就直接重新计算index,移到对应的位置即可,关键是这里要是个链表或者红黑树,怎么办。
-
链表迁移
拆分链表,一个lo,一个hi,lo是扩容后计算index位置不变的元素,hi是计算index位置需要变化的元素。
这里举个例子,比如初始长度为16,有a,b两个元素,a,b的hash分别为2和18,所以他们都在index为2的bin中。但是现在要扩容了,tab长度为32,a的hash是2,所以index依然为2,但是b的hash是18,所以index是18,b需要放到新的位置了。
这里源码中的位运算用的比较帅:
if ((e.hash & oldCap) == 0) { // lo add } else { // hi add }稍微解释一下,如果length为16,那么意味着e.hash只关注后四位,如果length为32,那么意味着e.hash只关注后五位。
所以e.hash这时候要看看第5位是否和自己是一样的。
如果是,那么意味着新tab中计算元素e的index是会和之前不一样的,这部分元素被放到hi链表中。
如果不是,那么就是和之前的index一致的,这部分元素会被放到lo链表中。
if (loTail != null) { loTail.next = null; newTab[j] = loHead; //lo不变 } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; //hi变 } -
红黑树迁移
同理,这里对红黑树也进行了拆分,当红黑树节点元素小于等于6的时候,才调用untreeify方法转换回链表。注意!这是整个hashmap中唯一在元素小于等于6的时候才退化的情况。另一个情况是removeNode直至list为空,才退化。
也就是说,使用remove操作并不会退化红黑树,除非把这个bin清空了。唯一真正退化的时候是resize里的split方法调用的时候!
-
-
线程安全性
这是个很无聊的问题,一个设计之初本就没有考虑线程安全的数据结构,与其去问为什么它线程不安全,不如去问它的线程安全版本ConcurrentHashMap是怎么实现的。
但是这里还是得总结一下hashmap的线程不安全场景。
-
put导致元素丢失
可以理解,当多个元素同时定位到一个桶,e.next = a 和 e.next = b后者会被覆盖,所以会丢失。
-
扩容导致无限循环(1.7)
1.7是头插法,所以扩容会导致无限循环。
-
put时扩容,get可能会null
废话,扩容的时候要迁移,人家没迁移好你去get能get到吗?
-
3.JDK1.8与JDK1.7的对比
-
结构区别,不多BB。
-
哈希算法区别
1.8的哈希算法是由每个对象的hashcode计算来的,所以是final 固定的。
1.7的哈希算法是由hashseed种子计算来的,所以不固定,重hash效率低。
-
扩容的区别,不多BB。
- 1.7头插,1.8尾插
ConcurrentHashMap 1.7
ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦初始化就不能改变,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。
ConcurrentHashMap 1.8
- 细粒度锁,只锁bin头
- size模仿longadder
- 并发扩容